

Unlock faster and efficient justification with Phi-4-Flash-Reasoning-Optimized for Edge, Mobile and Real-Time.
The most modern architecture redefines the speed for thinking models
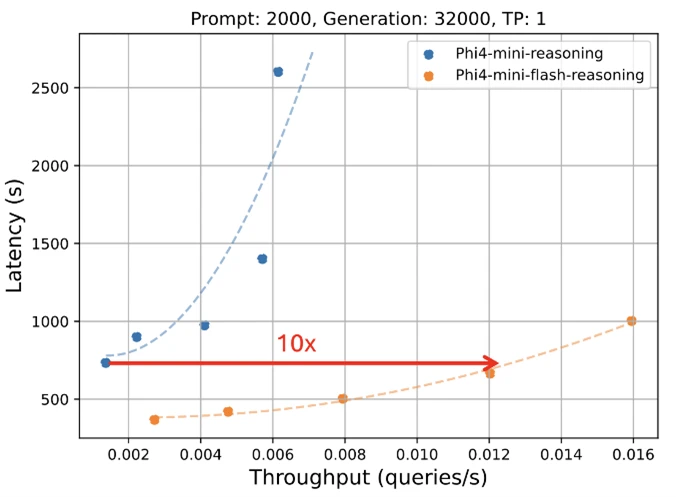
Microsoft is enthusiastic about the new release of the PHI models: Phi-4-Mini-Flash-Reasoning. This new model is created for scenarios where calculation, memory and latency are fixed, and are designed to bring advanced capacity to marginal devices, mobile applications and other sources. This new model follows the Phi-4-Mini, but is based on a new hybrid architecture that reaches up to 10 times higher throughput and 2 to 3 times the average reduction in latency, enabling nordicne-faster derivation without sacrificing consumption. Prepared to power the solution of the real world that requires efficiency and flexibility is on Azure AZ Foundry, NVIDIA API and hugging the face and hugging the face and today it is available.
Efficiency without compromise
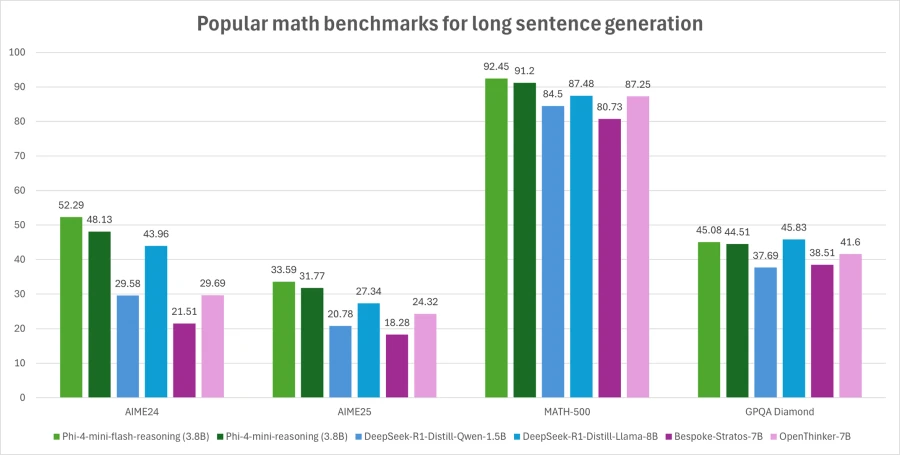
Phi-4-Mini-Flash-Reasoving Balances Mathematical Consistent ability with effectiveness, so it is potential to observe educational applications, logical applications in real time and more.
Like its predecessor, the Phi-4-Mini-Flash-Reasoning is 3.8 billion parameters open model optimized for advanced mathematical thinking. It supports the length of 64 KB and is fine -tuned to high -quality synthetic data to provide reliable logically demanding performance.
What is new?
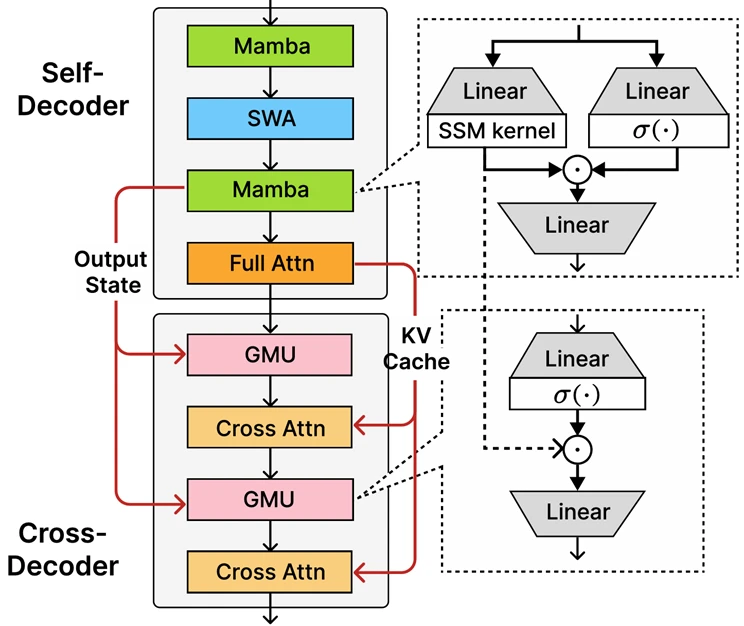
At the core of the Phi-4-Mini-Flash-Deasoning is a newly introduced decoder-hybrid-decoder architecture whose central innovation is a taken memory unit (GMU), a simple but effective mechanism for sharing representations between layers. Architecture includes a separate decoder that Mamba (model space model) and SWAs (SWA), along with only full attention. Architecture also includes a cross decoder, which interleaves expensive layers of cross attention with a new, efficient GMU. This new architecture with GMU modules drastically improves decoding efficiency, increases the context of searching for a long time, and allows architecture to provide exceptional performance in a number of tasks.
Sambay architecture’s key advantages include:
- Increased decoding efficiency.
- Prefilling time of complexity of linear summons.
- Increased scalabibility and increased long context performance.
- Up to 10 times higher throughput.
Benchmarks knowing Phi-4-by-Flash
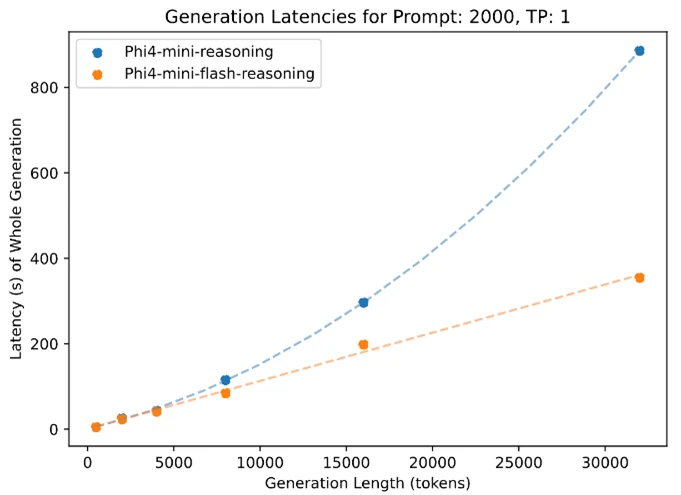
Like all models in the Phi family, on one GPU, the remaining remains of the Phi-4-Mini-Flash, which is accessible for a wide range of cases of use. What is different is his architectural advantage. This new model achieves significant lower latency and higher permeability compared to Phi-4-Mini-Reasoning, especially in tasks with long context and justification sensitive to latency.
This makes the Phi-4-Mini-Flash-Reasoning option for developers and businesses that want to deploy intelligent systems that require fast, scalable and efficient up-beyond or devices.
What are the potential use of boxes?
Due to reduced latency, improved throughput and focus on mathematical reasoning, the model is ideal for:
- Adaptive teaching platformwhere the feedback loops are necessary in real time.
- Assistants of thinking about equipmentSuch as mobile study aids or logical agents based on the edge.
- Interactive tutoring systems That it dynamically adjusts the content of the pupil’s performance.
Thanks to its strength in mathematics and structured reasoning, it is particularly valuable for educational technologies, light simulations and automated evaluation tools that require reliable logical inference with rapid response times.
Developers are advised to associate with peers and Microsoft engineers through the Microsoft Community community to ask questions, share feedback and explore cases in the real world together.
Microsoft’s commitment to trusted AI
Organizations across industries are used by Azure AI and Microsoft 365 Copilot Capatibility for increasing growth, increasing productivity and creating value added experiences.
We have committed to helping to use and build AI, which is trustworthy, which means it is safe, private and safe. We bring proven procedures and knowledge of decades of research and creating AI products in scale to provide leading commitments and capacitors that cover our three pillars of security, privacy and security. Trust AI is only perhaps if you combine our obligations such as our safe future initiative and responsible for the principles, with our product capabilities to unlock the transformation of AI with confidence.
Phi models are developed in accordance with Microsoft AI principles: responsibility, transparency, justice, limitations and security, privacy and security and inclusion.
The Phi family, including the Phi-4-Mini-Flash-Reasoning, uses a robust security strategy after training, which integrated under the supervision of fine fine-tuning (SFT), optimizing direct preference (DPO) and strengthening human feedback (RLHF). These techniques are used by a combination of open source and proprietary data sets, with a strong emphasis on eningry, minimizing harmful outputs and solving a wide range of security categories. Developers are recommended to apply responsible proven procedures AI adapted to their specific use and cultural contexts.
Read a model card and learn more about any risk strategies and alleviation.
Find out more about the new model
Create with Foundry Azure AI
(Tagstotranslate) ai