


|
Modern organizations manage data across several disconnected systems – structured databases, unstructed files and separate visualization tools – creating barriers that slow analytical workflows and reduce the generation of knowledge. Separate visualization platforms often create barriers that prevent teams from extraction of complex business knowledge.
These unconnected workflows prevent your organizations from maximizing data investment and create a delay in decision -making and missed opportunities for understanding the analysis that more data.
From today, you can use three new skills to speed up your journey from raw data to action information in Amazon Sagemaker:
- Amazon QuickSight integration – Start the Amazon QuickSight directly from the Amazon Sagemaker Unified Studio to create dashboards using your project data, then publish them in the Amazon Sagemaker catalog for wider discovery and sharing across your organization.
- Amazon Sagemaker adds support for Amazon S3 generally the purpose of buckets and Amazon S3 Access GRANTS IN SAGEMaker Catalog-Make data stored in the Amazon S3 buckets General purposes for teams to find, access and collaborate on all data types include non -structural data, while the HAPNOFINGS ACCESS ACCESS S3 ACCESS GRANTS.
- Automatic data on board from your Lakehouse – Automatic loading of existing data sets Data Glue (GDC) from Lake architecture to SageMaker catalog, without manual settings.
These new Sagemaker abilities are engaged in a complete data cycle of data in unified and controlled experience. You will get automatic decks of existing structured data from your lakehouse, trouble -free cataloging of non -structural data in the Amazon S3 and efficient visualization through a quick view – all with the composition of controls and access.
Let’s take a closer look at every ability.
Amazon Sagemaker and Amazon QuickSight Integration
With this integration, you can build QuickSight in Amazon using data from your Amazon Sagemaker projects. When you launch QuickSight from Amazon Sagemaker Unified Studio, Amazon Sagemaker automatically creates QuickSight data file and organizes it in a secure folder only accessible to the project members.
In addition, the control panels that you build remain in this folder and automatically appear as assets in your SageMaker project, where you can publish them in the SageMaker catalog and share them with users or groups in your company directory. This keeps your dashboard organized, discovered and controlled in the unified studio sagemaker.
To use this integration, both your Amazon Sagemaker Unified Studio Domain must be integrated with the AWS Iam Identity Center using the same instance Iam Identity Center. In addition, your QuickSight account must exist in the same AWS account where you want to allow a quick view plan. You can learn more about the assumptions on the documentation page.
After putting these assumptions, you can enable the Amazon QuickSight navigation plan to the Amazon Sagemaker and Selection Blueprints Tab. Then find Amazon QuickSight and follow the instructions.

You must also configure your SQL Analytics Project Profile to include Amazon QuickSight in Add BluePrint deployment settings.
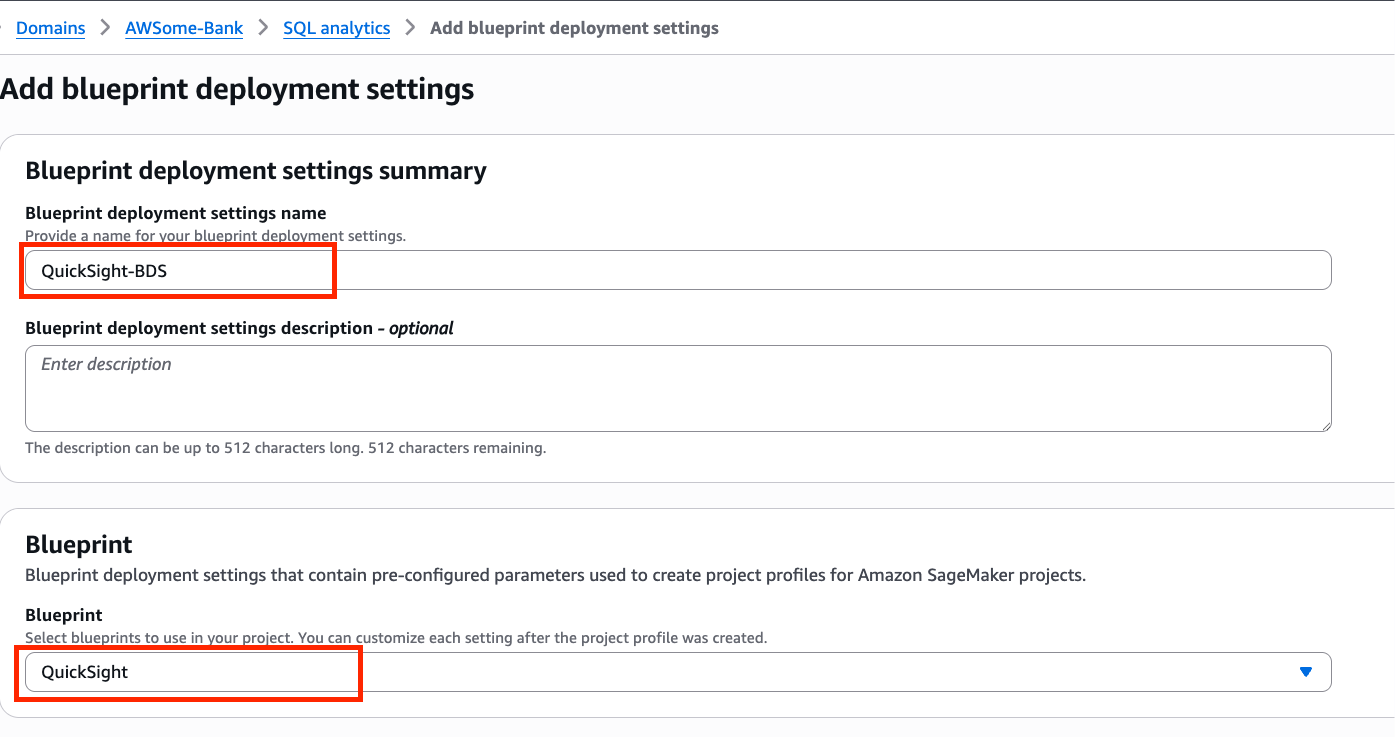
If you want to learn more settings on board, Fer on the documentation page.
After you create a new project, you must use SQL Analytics profile.
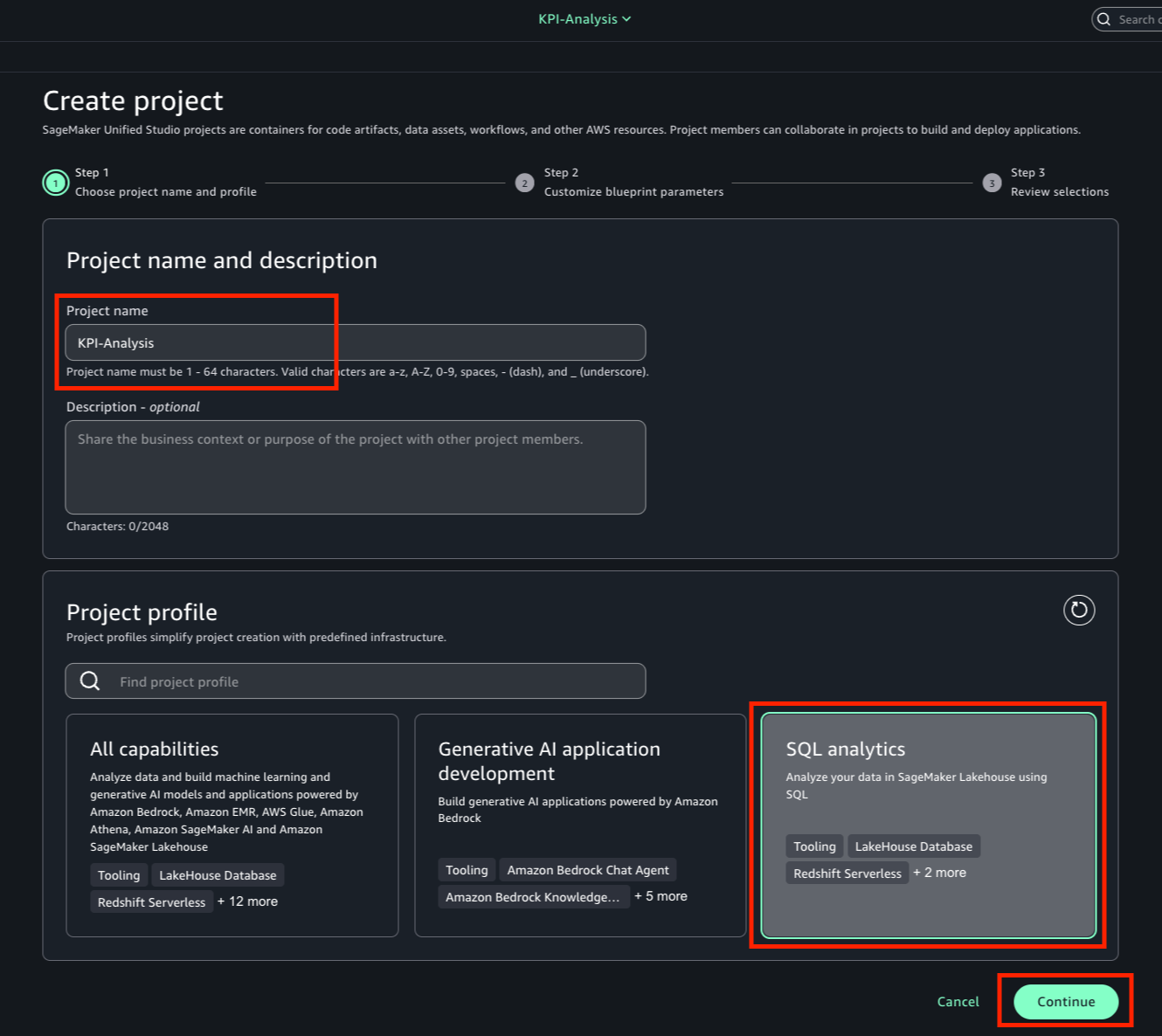
With the project created, you can start building visualizations with a quick view. You can navigate to Data tab, select table or view for visualization and select Open in a quick view under Action.
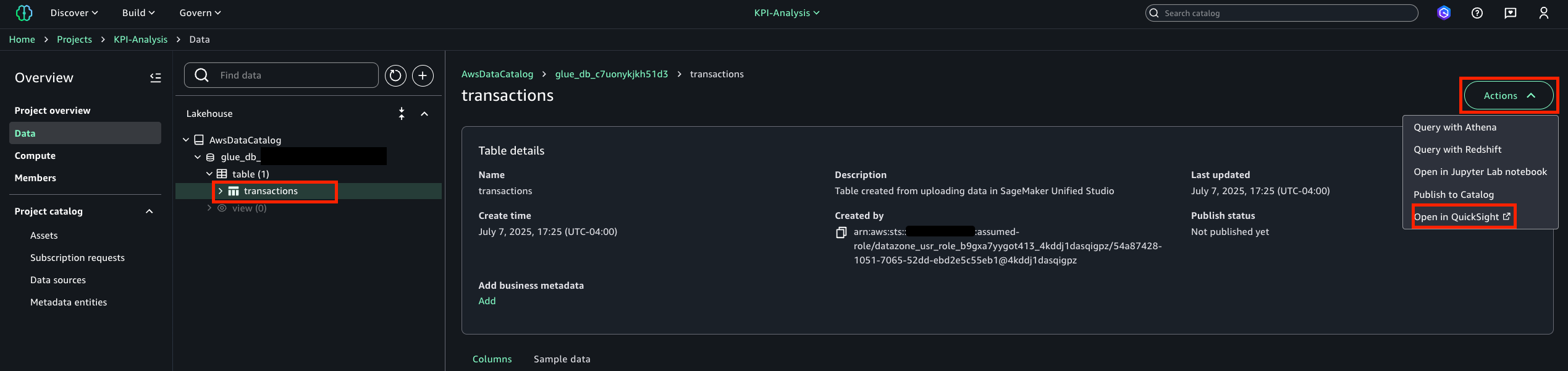
This will redirect you to a quick look at Amazon transaction The data file page and you can choose Use in analysis You want to start examining data.
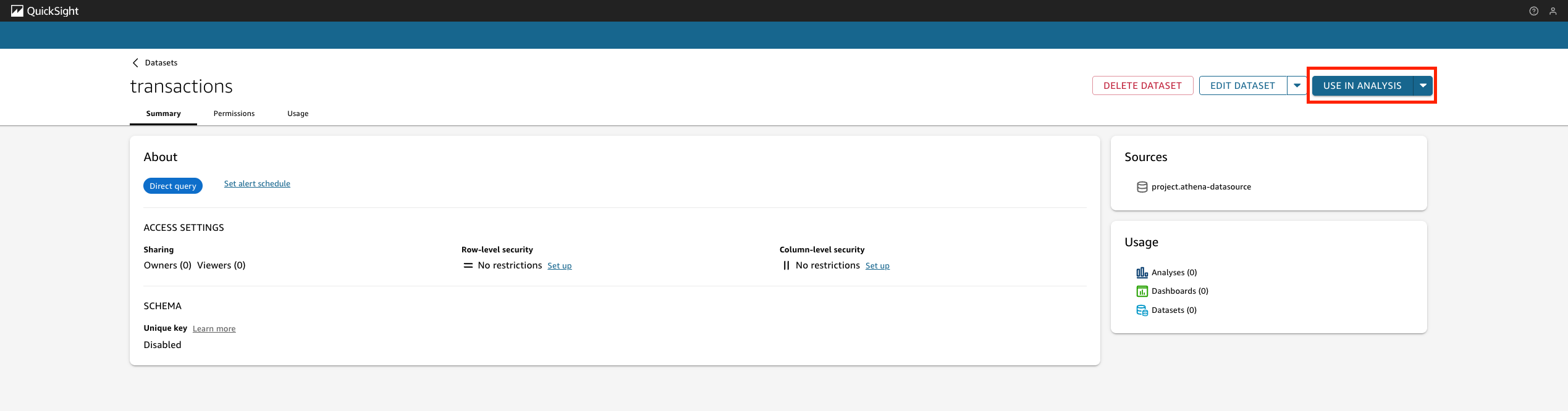
When you create a project with a QuickSight plan, the Sagemaker Unified Studio automatically establishes a limited rapid view of the project, where the sagemaker will scatter all priests – analyzes, data sets and dashboards. Synchronization of the Integration Folder Maintenance in real time, which maintains access permissions for a quick view in accordance with project membership.
Amazon Simple Storage Service (S3) General Purpose of Integration of Kbely
As of today, Sagemaker has added support for general S3 buckets in the SageMaker catalog to increase discovery and allow granubs permission through granters to access S3, enably users to data control, including sharing and authorization management. Data consumers, such as data scientists, engineers and business analysts, can now discover and approach S3 assets via the SageMaker catalog. This expansion also allows data manufacturers to manage security checks on any S3 data asset via a single interface.
If you want to use this integration, you need appropriate S3 buckets and your SageMaker Unified Studio projects must have access to S3 buckets containing your data. For more information about the assumptions, see the Amazon S3 data on the Amazon Sagemaker Unified Studio Documentation Page.
You can add a connection to an existing S3 bucket.
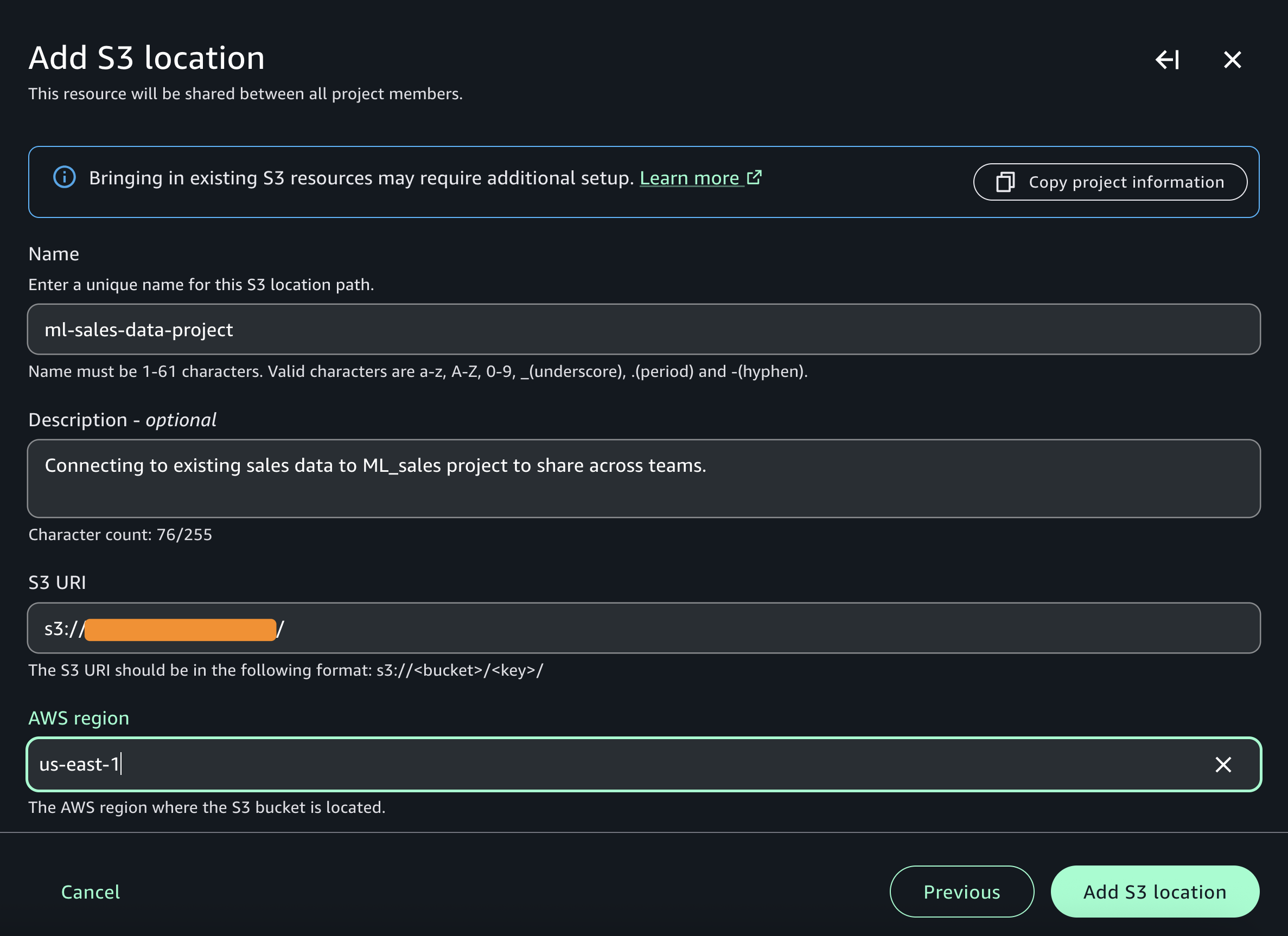
When it is connected, you can browse accessible folders and create discoverable assets by selecting on a bucket or folder and selecting Catalog.
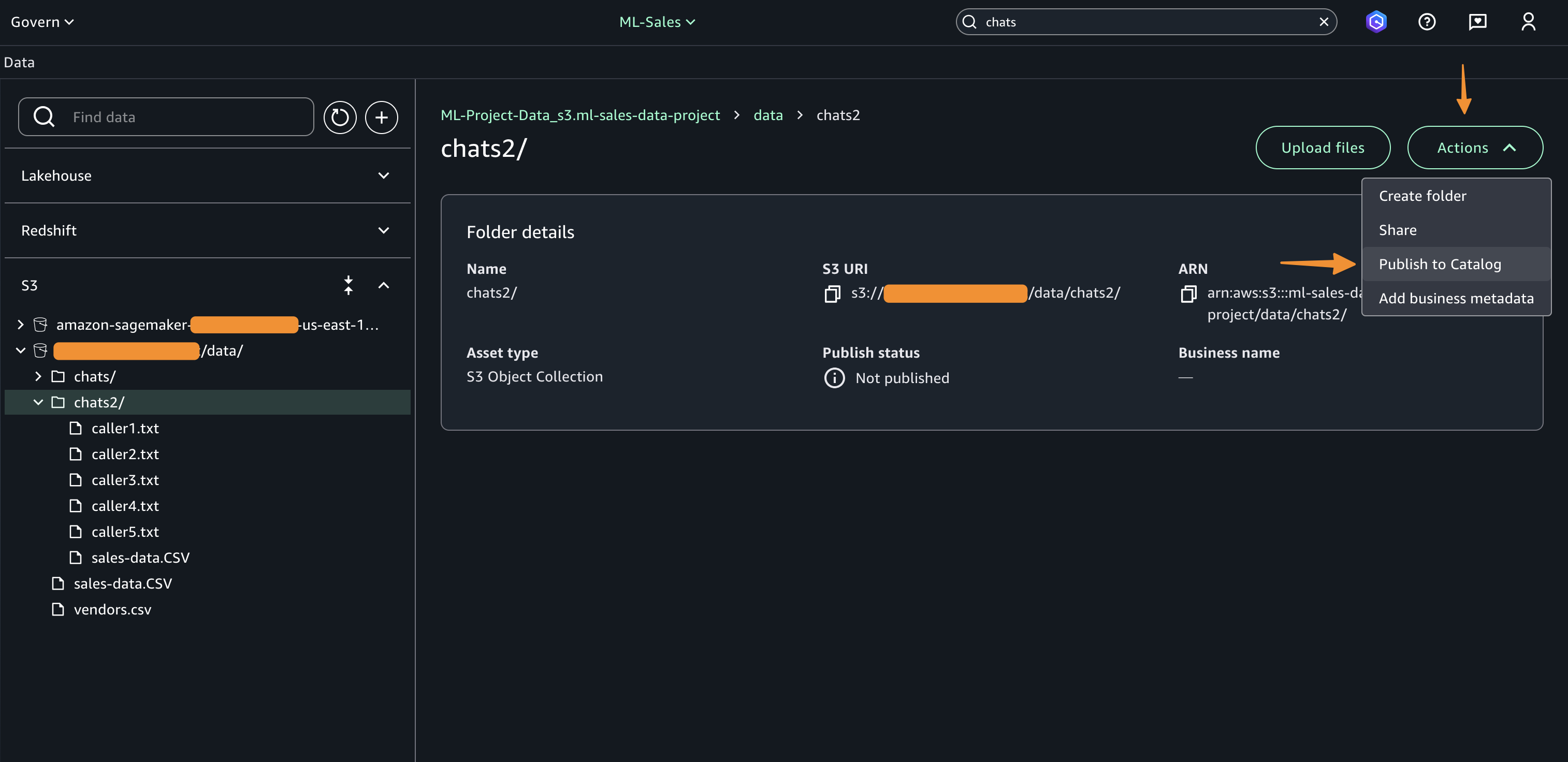
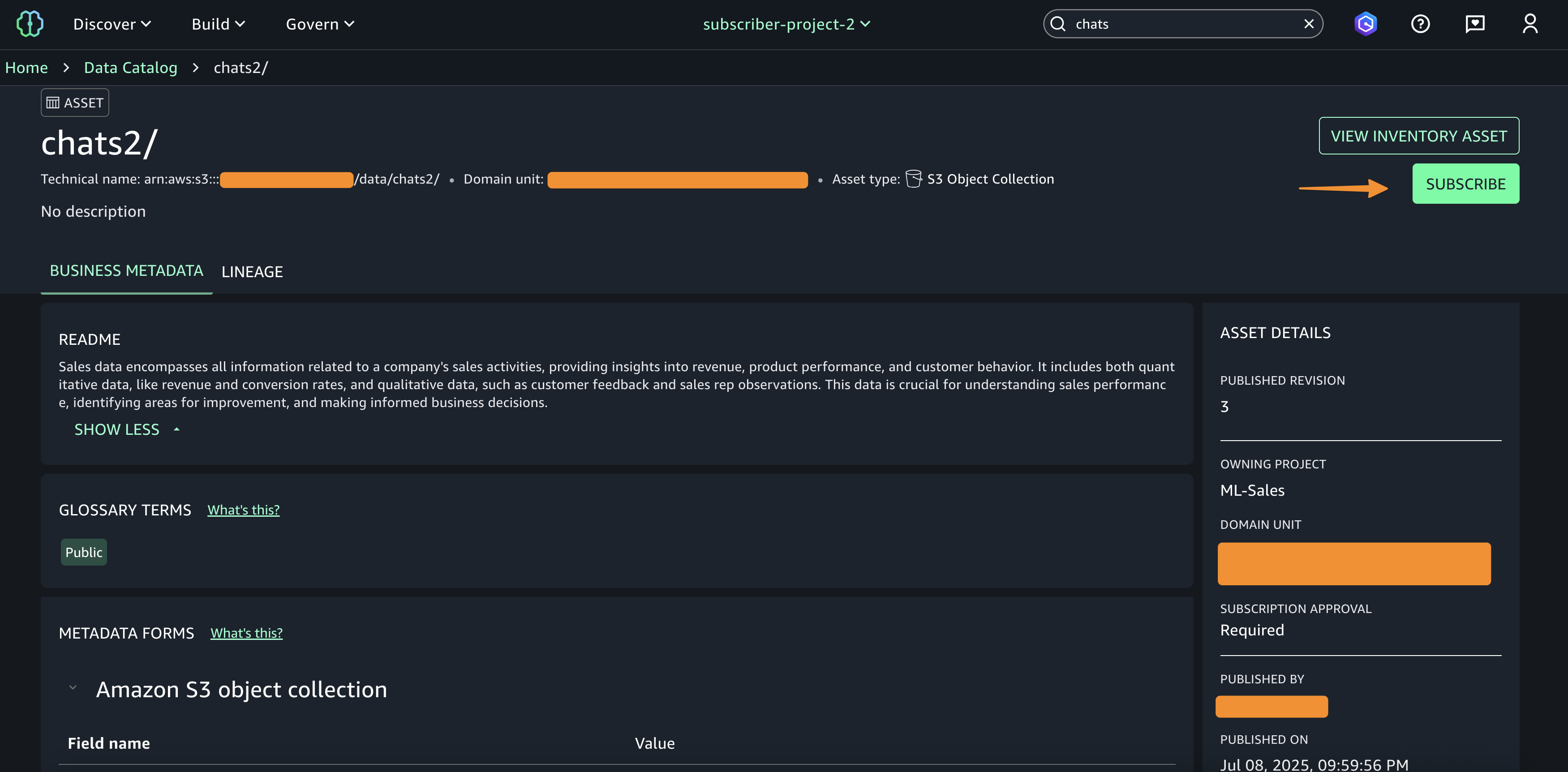
This action creates a catalog asset shagemaker type “Object collectors S3” and on the page details of open assets, where users can increase the business context to improve search and discovery. Unce, data consumers can discover and subscribe to these cataloged assets. When data consumers subscribe to the “S3 collection” assets, the SageMaker catalog automatically grants access to access to S3 after approval, allowing cooperation across the team and having the correct access to the correct users.
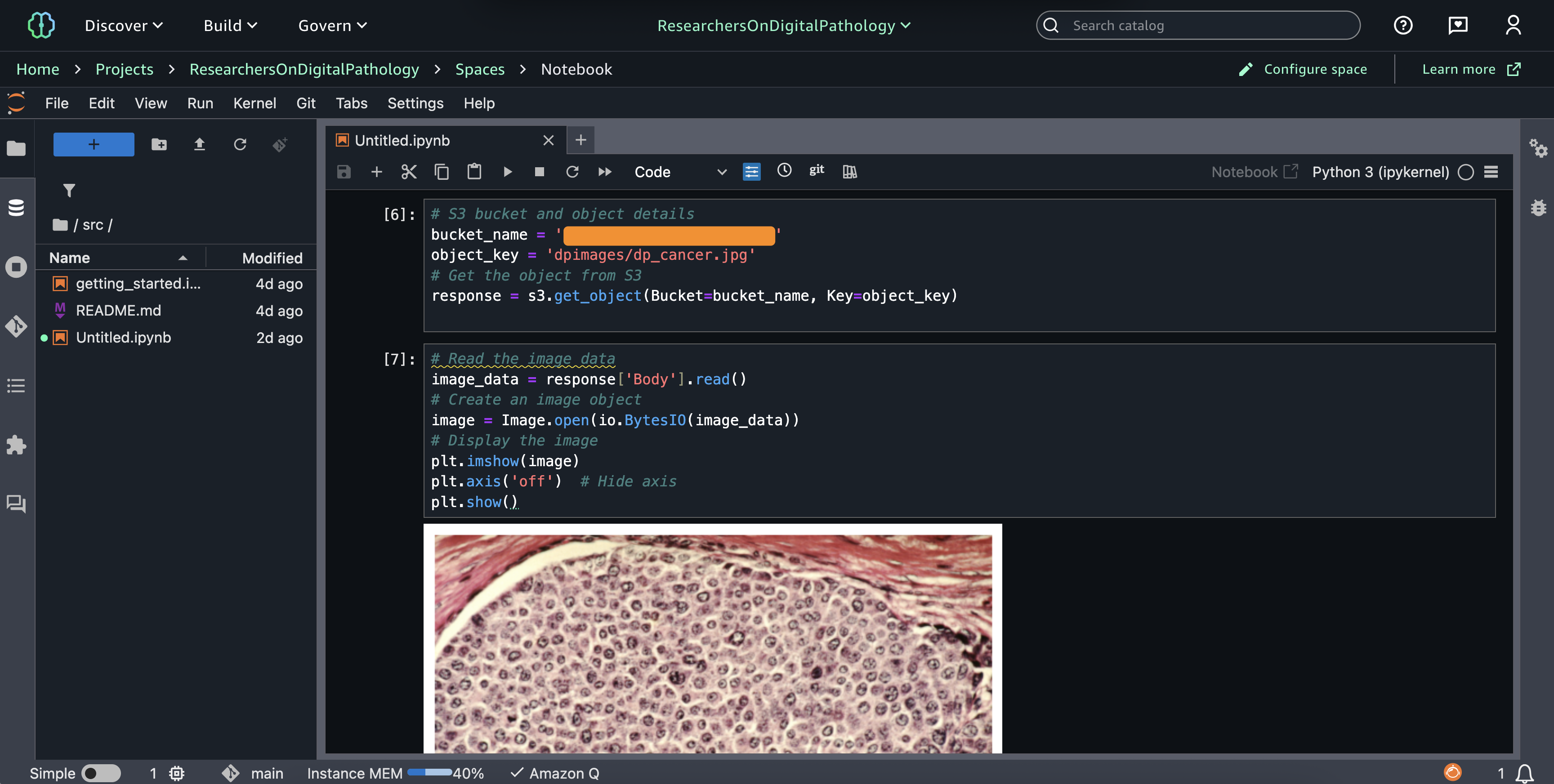
If you have access, you can now process non -composition data in the Amazon Sagemaker Jupyter. The screen is examined for image processing in case of medical use.
If you have structured data, you can ask your data using Amazon Athena or the process using Spark in laptops.
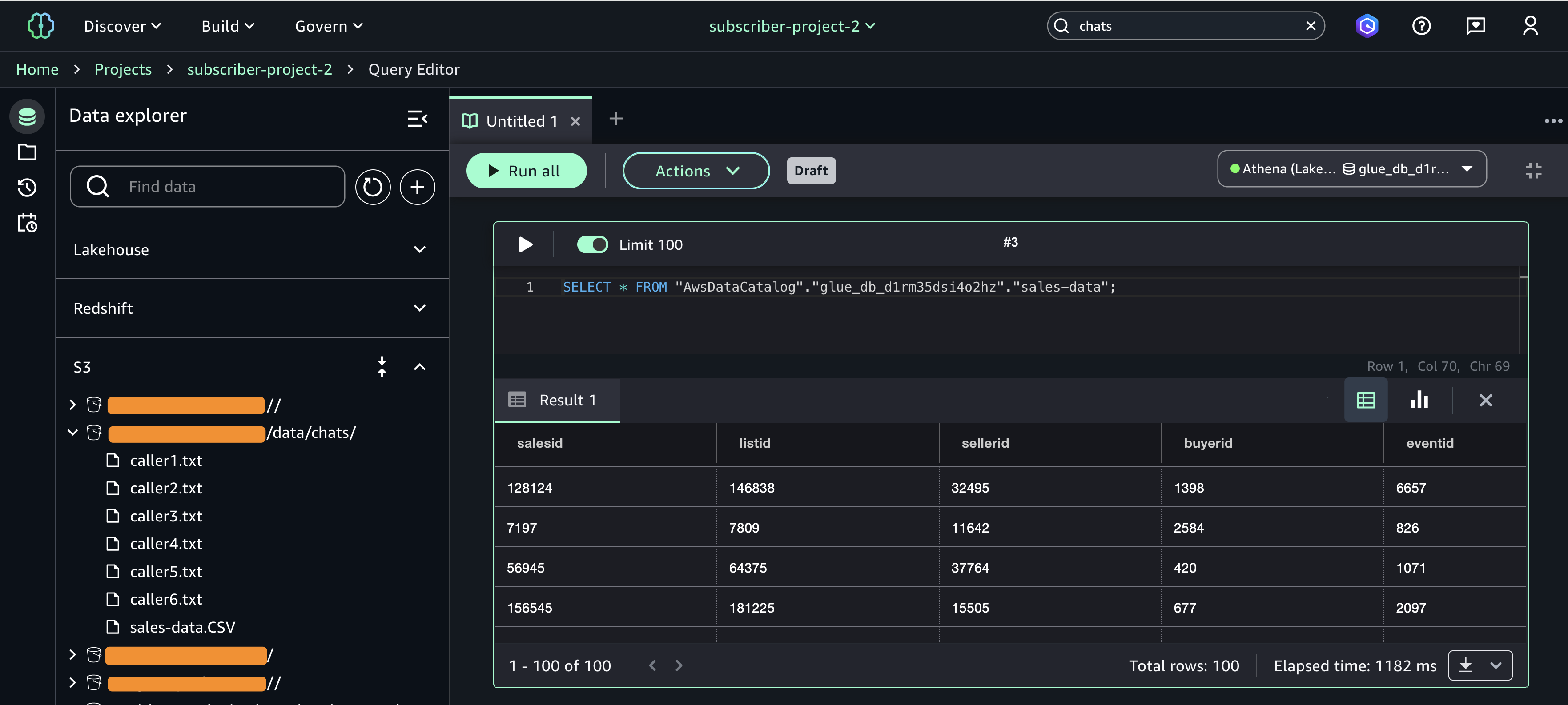
With this approach, you can smoothly integrate data S3 into my work streams through access to S3 access – analyzing them into laptops and combining them with structural data in Lake and Amazon Redshift for comprehensive analysts. In JUPYTERLAB, you can access non -comprehensive data such as documents, images to train ML or generate questionable knowledge.
Automatic data on board from your Lakehouse
This integration automatically encounters all your Lake data sets into the SageMaker catalog. The key advantage for you is to bring data sets Data Data AWS Glue (GDC) to the SageMaker catalog, eliminate manual settings for cataloging, sharing and editing them centrally.
This integration requires existing Lakehouse settings with a data catalog containing a structured data set.
When you set the Sagemaker domain, the Sagemaker catalog automatically receives metadata from all the Lake databases and tables. This means that you can explore Immatelley and use Dataets from the Wedin Sagemaker Unifed Studio with ITIT configuration.
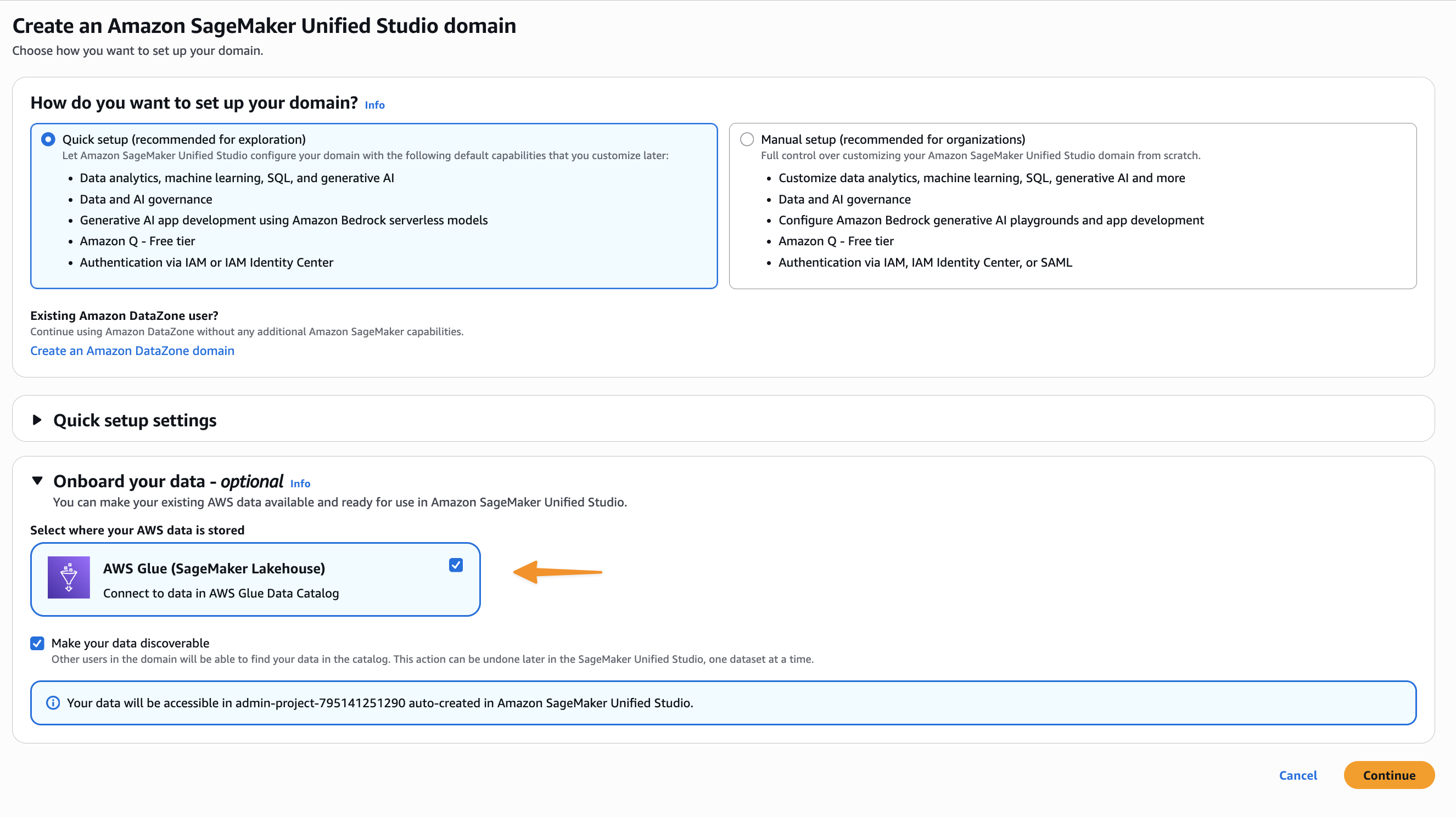
Integration will help you start managing, manage and consume these assets from the Unified Studio SageMaker, App -Student Access Management and Control Policy that you can use for other types of data to unify technical and business metadata.
Other things to know
Here are a few things that you can note:
- Availability – These integrations are available in all AWS commercial regions where Amazon Sagemaker is supported.
- Prices – Standard Sagemaker Unified Studio, Quicksight and Amazon S3 Pricking Applied. No additional fees for integration itself.
- Documentation – In the Sagemaker Unified Studio documentation you will find a complete setting wizard.
Start with these new integrations through Amazon Sagemaker Unified Studio Console.
Happy building!
– Donnie